Вернуться к блогу

Большие языковые модели (Large Language Model) — особый класс систем искусственного интеллекта, которые умеют работать с человеческим языком. Их главная задача — понимать и создавать тексты на естественном языке, то есть на том, на котором мы общаемся в повседневной жизни.
Для работы LLM используют масштабные наборы текстовых данных, на которых они обучаются. Для этого используются самые разные источники: книги, научные публикации, новости, сайты, форумы и многое другое. За счет такого масштабного охвата информации система учится распознавать смысл слов и предложений, улавливать контекст, запоминать факты и закономерности построения предложений в языке.
Появление LLM стало настоящим технологическим скачком для искусственного интеллекта. Если раньше ИИ мог работать только в строго определенных областях, то сегодня большие языковые модели справляются с задачами самого разного типа — от рутинных до творческих.
Современные большие языковые модели построены на архитектуре трансформеров, которая была впервые представлена в 2017 году и кардинально изменила подходы к обработке последовательной информации, такой как текст. Основные элементы LLM:
Входной слой. На первом этапе текст пользователя преобразуется из привычного человеку вида в числовые векторы — так называемые эмбеддинги. Это необходимо для того, чтобы нейронная сеть могла работать с текстовой информацией на своем «языке» — языке чисел.
Механизм внимания (Attention). Ключевая инновация трансформеров — система внимания. Она позволяет модели выделять те слова или символы, которые наиболее значимы для правильного понимания смысла предложения или абзаца. Благодаря этому LLM способны улавливать сложные связи и контекст.
Многоуровневые нейронные слои. После этапа внимания данные проходят через серию глубоких нейронных слоев. Каждый слой обрабатывает информацию на своем уровне абстракции: одни «замечают» грамматические закономерности, другие — смысловые нюансы и скрытые зависимости между словами.
Выходной слой. На финальном этапе генерируется окончательный результат — будь то продолжение текста, ответ на вопрос, перевод или выполнение другой поставленной пользователем задачи.
В отличие от предыдущих методов, трансформеры позволяют эффективно анализировать длинные фрагменты текста, учитывая взаимосвязи между всеми словами вне зависимости от их удаленности друг от друга.
Современные языковые модели отличаются невероятными размерами: количество их параметров — то есть внутренних настроек и связей — может достигать сотен миллиардов. Такой масштаб позволяет моделям «усваивать» огромные объемы информации из обучающих данных и использовать их для генерации осмысленных, релевантных и разнообразных текстов.
Сегодня крупные языковые модели активно интегрируются в разные сферы, существенно расширяя возможности автоматизации и интеллектуальной обработки информации. Вот лишь некоторые из направлений, где LLM находят практическое применение:
Автоматизация общения с пользователями. Чат-боты и виртуальные ассистенты способны вести осмысленный диалог с пользователями, отвечать на вопросы, решать проблемы.
Создание и редактирование текстов. Генерация статей, новостей, писем, резюме, рекламных слоганов.
Переводы на другие языки. Автоматический перевод между языками с учетом контекста.
Поиск информации и суммаризация. Быстрый поиск релевантных данных и сжатое изложение сути.
Обработка юридических документов. Анализ контрактов, поиск рисков, автоматизация составления документов.
Медицинские консультации. Поддержка врачей при анализе симптомов и историй болезни.
Образование. Помощь в обучении, создание учебных материалов, автоматизация проверки знаний.
Креативные задачи. Написание стихов, рассказов, сценариев.
Таким образом, большие языковые модели становятся универсальным инструментом для автоматизации интеллектуального труда и расширения возможностей специалистов во множестве отраслей.

Большие языковые модели (LLM) значительно расширяют возможности автоматизации и интеллектуальной поддержки при разработке ПО.
LLM позволяют разработчикам быстро создавать рабочие куски кода прямо из обычного описания задачи, снижая нагрузку и ускоряя разработку. Они также помогают анализировать и разъяснять чужой код, что повышает эффективность работы над сложными проектами и изучение новых технологий.
Они автоматически находят ошибки и подсказывают варианты исправлений, улучшая как производительность, так и читаемость кода. А также берут на себя рутинные дела, создавая тесты, шаблоны и документацию, освобождая разработчиков для более интересных и важных задач.
Еще одно перспективное направление — автоматический перевод кода между разными языками программирования. LLM способны адаптировать алгоритмы и структуры данных под синтаксис другого языка, что существенно облегчает миграцию проектов и интеграцию с новыми технологиями.
Современные большие языковые модели (LLM) основаны на ряде фундаментальных принципов, которые определяют их эффективность и универсальность.
Обработка последовательностей. Модель анализирует не только отдельные слова, но и их взаимосвязь в предложении или абзаце.
Внимание к контексту (Self-Attention). Каждое слово оценивается с учетом окружающих его слов — так модель «понимает» смысл фразы.
Глубокое обучение (Deep Learning). Многослойные нейронные сети выявляют сложные закономерности в текстах.
Обобщение знаний. После обучения на большом объеме данных модель способна применять полученные знания к новым задачам.
Именно благодаря этим принципам большие языковые модели могут не только оперировать фактами из обучающего материала, но и рассуждать, делать предположения и создавать осмысленные тексты на самые разные темы.
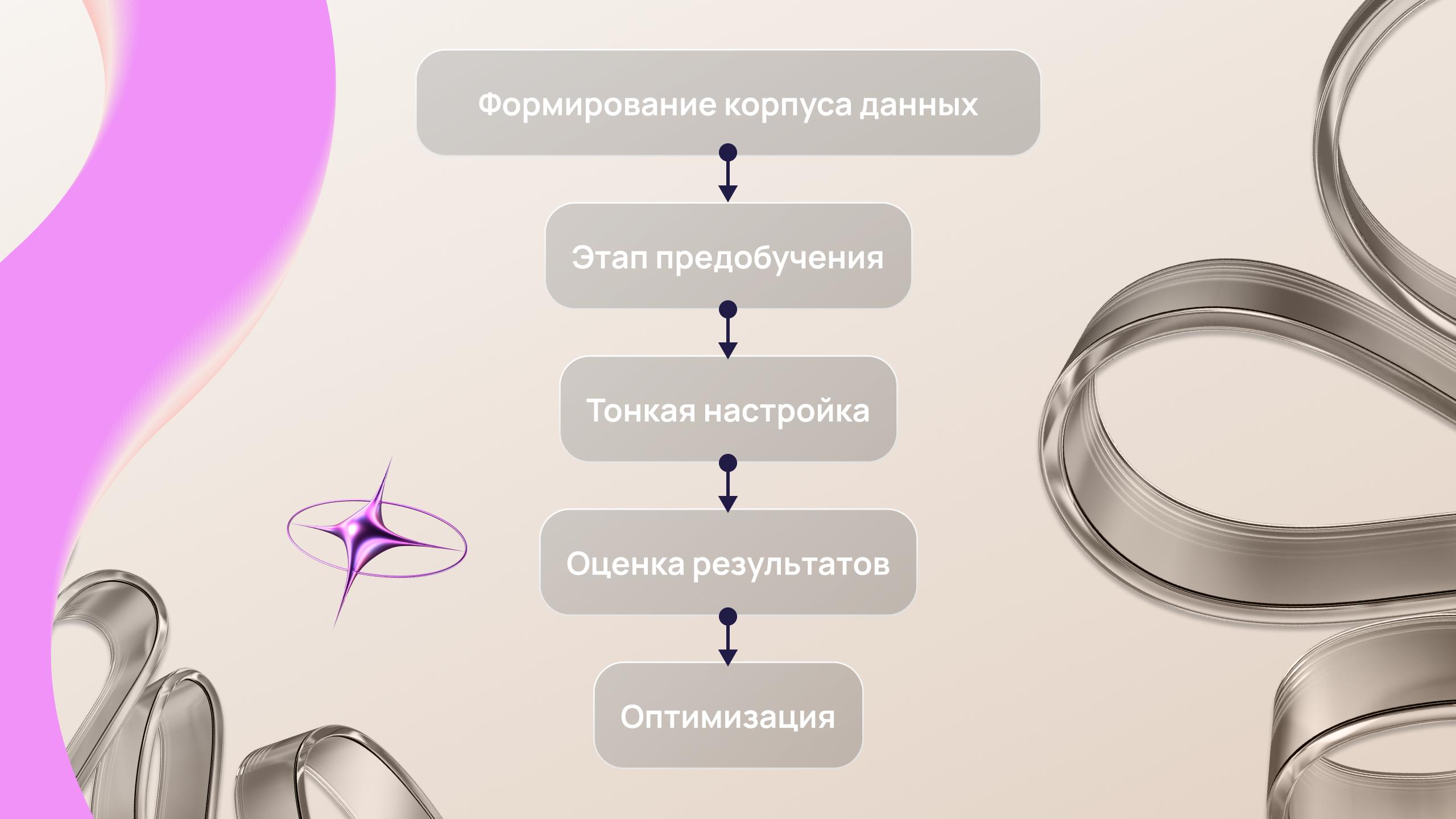
Обучение больших языковых моделей — это сложный процесс, включающий несколько ключевых этапов:
Формирование корпуса данных. На первом этапе собирается масштабная база текстов различного происхождения: художественная литература, научные публикации, интернет-ресурсы и др.
Этап предобучения. Далее система подвергается предварительному обучению. На этом этапе она учится понимать структуру языка, анализировать взаимосвязь между словами и предсказывать последующие фрагменты текста на основании предыдущих.
Тонкая настройка. После предобучения проводится дополнительная адаптация модели на специализированных датасетах.
Оценка результатов. Затем модель тестируют на независимых наборах данных. Это позволяет объективно оценить её способность давать точные и релевантные ответы.
Оптимизация. На заключительном этапе специалисты корректируют параметры модели для повышения её эффективности, минимизации ошибок и улучшения производительности.
Стоит отметить, что обучение таких моделей требует колоссальных вычислительных мощностей: для этого задействуются тысячи современных GPU, а сам процесс может продолжаться от нескольких недель до нескольких месяцев.
Большие языковые модели способны улавливать смысл текста благодаря сочетанию нескольких сложных механизмов:
Понимание контекста. Модель анализирует не только отдельные слова, но и их положение относительно других — учитывает, какие слова стоят до и после, чтобы правильно интерпретировать их значение в конкретной ситуации.
Семантическое представление. В процессе обработки текста формируются внутренние структуры, которые отражают смысл слов и целых выражений, позволяя различать даже тонкие нюансы значений.
Анализ синтаксиса. LLM обращает внимание на грамматические связи между словами, что помогает ей правильно понимать сложные предложения и распознавать роли отдельных частей речи.
Использование векторных представлений. Каждое слово преобразуется в уникальный числовой вектор (эмбеддинг), который отражает его смысловые и ассоциативные связи с другими словами.
Благодаря такому комплексному подходу языковые модели умеют различать слова-омонимы, адекватно реагировать на сложные языковые обороты и улавливать скрытый подтекст, заложенный автором.
Генерация текста происходит поэтапно:
Пользователь задает запрос или тему.
Модель анализирует входной текст, определяет его смысл и цель.
На каждом шаге генерации модель выбирает наиболее вероятное следующее слово или символ на основе предыдущего контекста.
Процесс повторяется, пока не будет достигнута заданная длина ответа или выполнена поставленная задача.
Чтобы избежать однообразия или бессмысленных повторов, используются специальные алгоритмы управления генерацией:
Temperature — параметр «творчества»: при низких значениях модель выбирает самые вероятные слова, при высоких — экспериментирует с менее очевидными вариантами.
Top-k sampling — ограничивает выбор следующего слова только k наиболее вероятными вариантами.
В результате LLM могут создавать связные тексты практически любой тематики и стиля.
С развитием LLM вопросы безопасности выходят на первый план:
Конфиденциальность данных — важно не допускать утечки личной информации пользователей при работе с моделью.
Фильтрация токсичного контента — современные модели снабжаются фильтрами для обнаружения и блокировки оскорбительных или нежелательных высказываний.
Контроль за фактологией — LLM могут генерировать правдоподобные, но вымышленные факты («галлюцинации»), поэтому требуется дополнительная проверка информации.
Защита от вредоносного использования — предотвращение генерации вредоносного кода или инструкций для противоправных действий.
Для повышения безопасности применяются методы анонимизации данных, регулярное обновление фильтров контента, внедрение многоуровневых систем контроля качества.
Прежде чем интегрировать большие языковые модели в свой бизнес-продукт, рекомендуется внимательно рассмотреть следующие моменты:
Соответствие задачам. Подходит ли LLM для ваших целей? Например, автоматизация поддержки клиентов или генерация отчетов.
Качество ответов. Достаточно ли точны и адекватны ответы модели для вашей сферы?
Стоимость внедрения. Расходы на интеграцию модели и необходимые вычислительные мощности.
Безопасность данных. Есть ли риски утечки информации?
Гибкость настройки. Можно ли дообучить модель под ваши задачи?
Легальность использования. Соблюдаются ли требования законодательства по обработке персональных данных?
Оценка этих аспектов поможет принять взвешенное решение о целесообразности внедрения LLM в ваш продукт или сервис.
Работа с большими языковыми моделями требует серьезной технологической базы. К основным требованиям на этапах обучения и эксплуатации относятся:
Мощные вычислительные кластеры, состоящие из тысяч графических процессоров (GPU) или специализированных тензорных процессоров (TPU).
Высокая пропускная способность сетей для обмена данными между узлами.
Значительные объемы оперативной памяти и дискового пространства для хранения обучающих данных и промежуточных результатов.
Для небольших моделей может быть достаточно одного сервера с современным GPU. Крупные модели зачастую требуют распределенных вычислений и масштабируемых облачных инфраструктур.
В случае массового использования предпочтение отдается облачным сервисам с возможностью динамического масштабирования.
С целью снижения затрат и повышения эффективности все чаще применяются методы уменьшения размера моделей (например, квантование и дистилляция), а также адаптация моделей под конкретные задачи с помощью дообучения.
Большие языковые модели становятся неотъемлемой частью нашей жизни, помогая упростить многие задачи и сделать нашу деятельность эффективнее и продуктивнее.



